Qu'est-ce qu'une couche de raisonnement déterministe pour les agents IA ?
Équipe Synalinks
Qu'est-ce qu'une couche de raisonnement déterministe pour les agents IA ?
Posez la même question deux fois à un agent IA, avec les mêmes données, et vous pourriez obtenir deux réponses différentes. Reformulez légèrement et vous en obtiendrez peut-être une troisième. Ce n'est pas un problème de prompt. C'est une propriété fondamentale du fonctionnement de la plupart des agents IA.
Les modèles de langage sont probabilistes. Ils prédisent le prochain token le plus probable en fonction d'une fenêtre de contexte. C'est puissant pour générer du langage naturel, mais c'est un problème quand vous avez besoin de réponses cohérentes et vérifiables.
Une couche de raisonnement déterministe résout ce problème en séparant le raisonnement de la génération. Au lieu de demander à un modèle de langage de trouver la réponse, vous lui fournissez une réponse déjà déduite par une logique à base de règles sur des connaissances structurées.
Même question. Mêmes données. Même réponse. À chaque fois.
Comment fonctionnent les agents IA probabilistes aujourd'hui
L'architecture standard des agents IA en production ressemble à ceci :
- Un utilisateur pose une question
- Le système récupère des documents pertinents par recherche de similarité vectorielle (RAG)
- Le contexte récupéré et la question sont envoyés à un modèle de langage
- Le modèle de langage génère une réponse
Cela fonctionne raisonnablement bien pour les questions ouvertes, la synthèse et les tâches créatives. Mais cela pose trois problèmes structurels pour les applications critiques :
Non-déterminisme. Les mêmes entrées peuvent produire des sorties différentes d'un appel à l'autre. Les réglages de température aident, mais même à température zéro, les mises à jour du modèle, l'ordre du contexte et les différences de tokenisation introduisent des variations.
Pas de chaîne de raisonnement. Le modèle ne montre pas son travail. Vous obtenez une réponse finale, mais vous ne pouvez pas retracer comment il y est arrivé. Si la réponse est fausse, vous ne pouvez pas identifier où le raisonnement a échoué.
Confusion entre recherche et raisonnement. Le modèle doit faire deux choses en même temps : déterminer quelles informations récupérées sont pertinentes, et raisonner dessus pour produire une réponse. Quand ces tâches sont mélangées, les erreurs se composent silencieusement.
Ce que fait différemment une couche de raisonnement déterministe
Une couche de raisonnement déterministe se place entre vos données et votre agent IA. Elle gère le raisonnement pour que le modèle de langage n'ait pas à le faire.
Voici l'architecture :
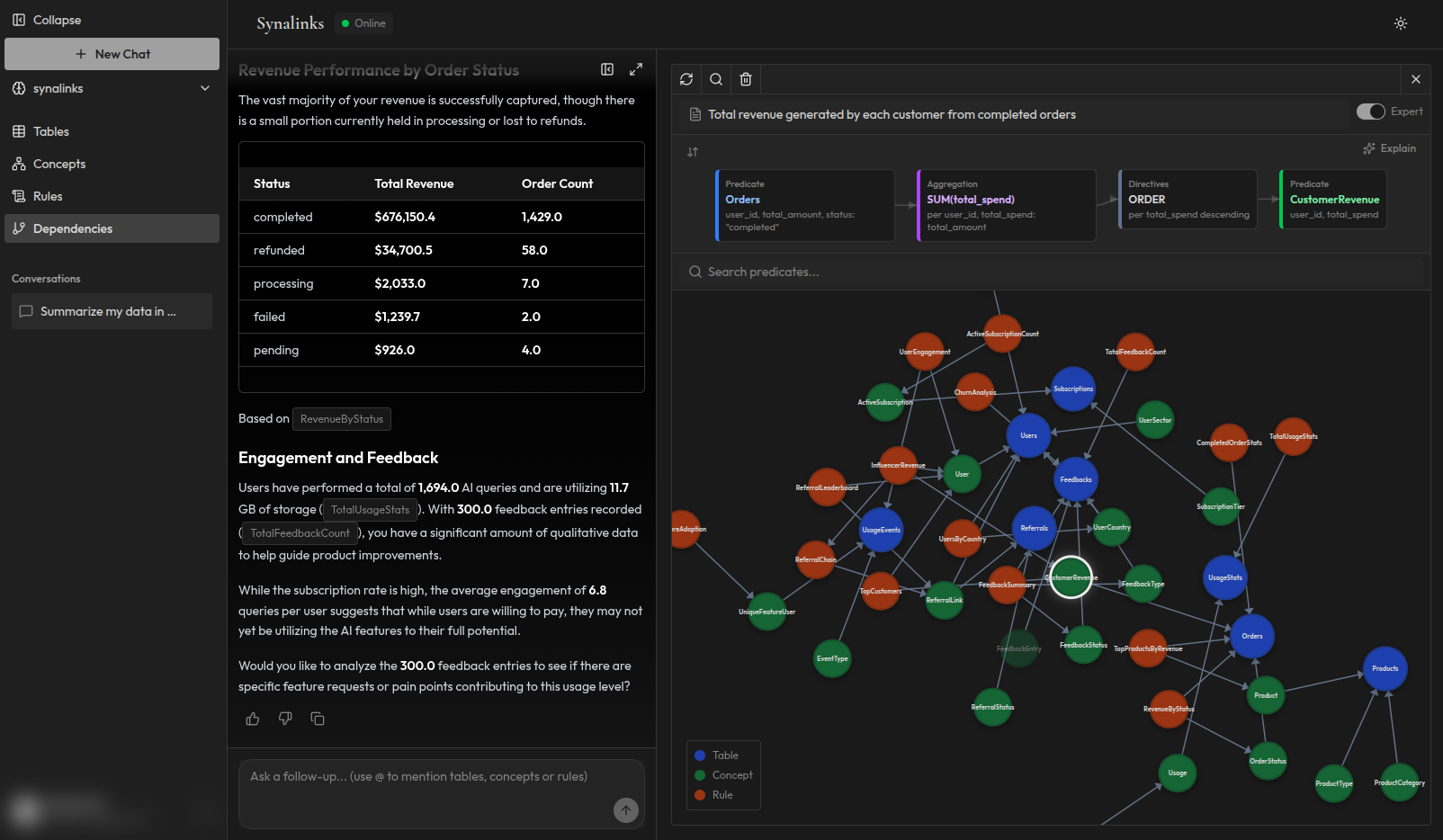
Étape 1 : Structurer les connaissances. Au lieu de stocker des documents sous forme d'embeddings vectoriels, vos données sont organisées en concepts, relations et règles vérifiés. Un client n'est pas juste un fragment de texte, c'est une entité avec des propriétés typées et des relations définies avec ses commandes, abonnements, tickets support, etc.
Étape 2 : Définir la logique. Les règles métier, les contraintes du domaine et les schémas de raisonnement sont encodés explicitement. « En retard » signifie plus de 30 jours après la date d'échéance. « À risque » signifie un client dont l'utilisation a chuté de 40% sur le dernier trimestre et qui a des tickets support non résolus. Ces règles ne sont pas enfouies dans des prompts. Ce sont des objets de premier ordre dans le système.
Étape 3 : Déduire les réponses. Quand une question arrive, le système applique les règles aux connaissances structurées et produit une réponse par déduction logique. Pas de prédiction de token. Pas de température. Pas de variation. La chaîne de raisonnement est capturée à chaque étape.
Le rôle du modèle de langage passe de « trouver la réponse » à « présenter la réponse en langage naturel ». Il reçoit le résultat déduit et le met en forme pour l'utilisateur. Le gros du travail, le raisonnement réel, s'est déjà produit de manière déterministe.
Pourquoi c'est important en pratique
Prenons un scénario concret. Vous faites tourner un agent IA pour l'équipe customer success d'une entreprise SaaS. Un membre de l'équipe demande : « Quels clients Enterprise risquent de churner ce trimestre ? »
Avec du RAG probabiliste : Le système récupère des fiches clients, des logs d'utilisation et des tickets support qui semblent pertinents selon la similarité vectorielle. Le modèle de langage parcourt les fragments récupérés et essaie de comprendre ce que « à risque » signifie dans ce contexte. Peut-être utilise-t-il une heuristique raisonnable. Peut-être en hallucine-t-il une. Vous obtenez une liste, mais vous ne pouvez pas vérifier les critères appliqués.
Avec une couche de raisonnement déterministe : Le système connaît déjà les relations structurées entre les clients, leurs plans, leurs métriques d'utilisation et leur historique de support. « À risque » est une règle définie : utilisation en baisse de 40%+ sur 90 jours ET tickets critiques ouverts ET date de renouvellement dans le trimestre en cours. Le système applique cette règle, retourne les clients correspondants, et montre la chaîne de raisonnement exacte pour chacun.
La différence n'est pas subtile. Une approche vous donne une supposition plausible. L'autre vous donne une réponse prouvable.
Déterministe vs. probabiliste : quand utiliser chacun
Une couche de raisonnement déterministe ne remplace pas les modèles de langage. Elle les complète en gérant les tâches où le déterminisme compte.
Utilisez le raisonnement déterministe quand :
- La réponse doit être la même à chaque fois pour les mêmes données
- Vous avez besoin d'une piste d'audit montrant comment la réponse a été déduite
- La question implique une logique multi-étapes sur des relations structurées
- La conformité réglementaire exige l'explicabilité
- Les mauvaises réponses ont des conséquences business réelles
Utilisez la génération probabiliste quand :
- Vous avez besoin de réponses créatives ou ouvertes
- La tâche est de la synthèse ou de la mise en forme en langage naturel
- Il n'y a pas de réponse unique « correcte »
- La question est exploratoire ou conversationnelle
Les systèmes de production les plus efficaces utilisent les deux. La couche de raisonnement gère la logique. Le modèle de langage gère la communication.
Comment Synalinks Memory implémente cela
Synalinks Memory est une couche de raisonnement déterministe conçue pour les agents IA. Elle fonctionne en trois étapes :
- Connectez vos sources de données. Bases de données, tableurs, fichiers, API. Synalinks extrait et structure automatiquement les connaissances en concepts, relations et règles vérifiés.
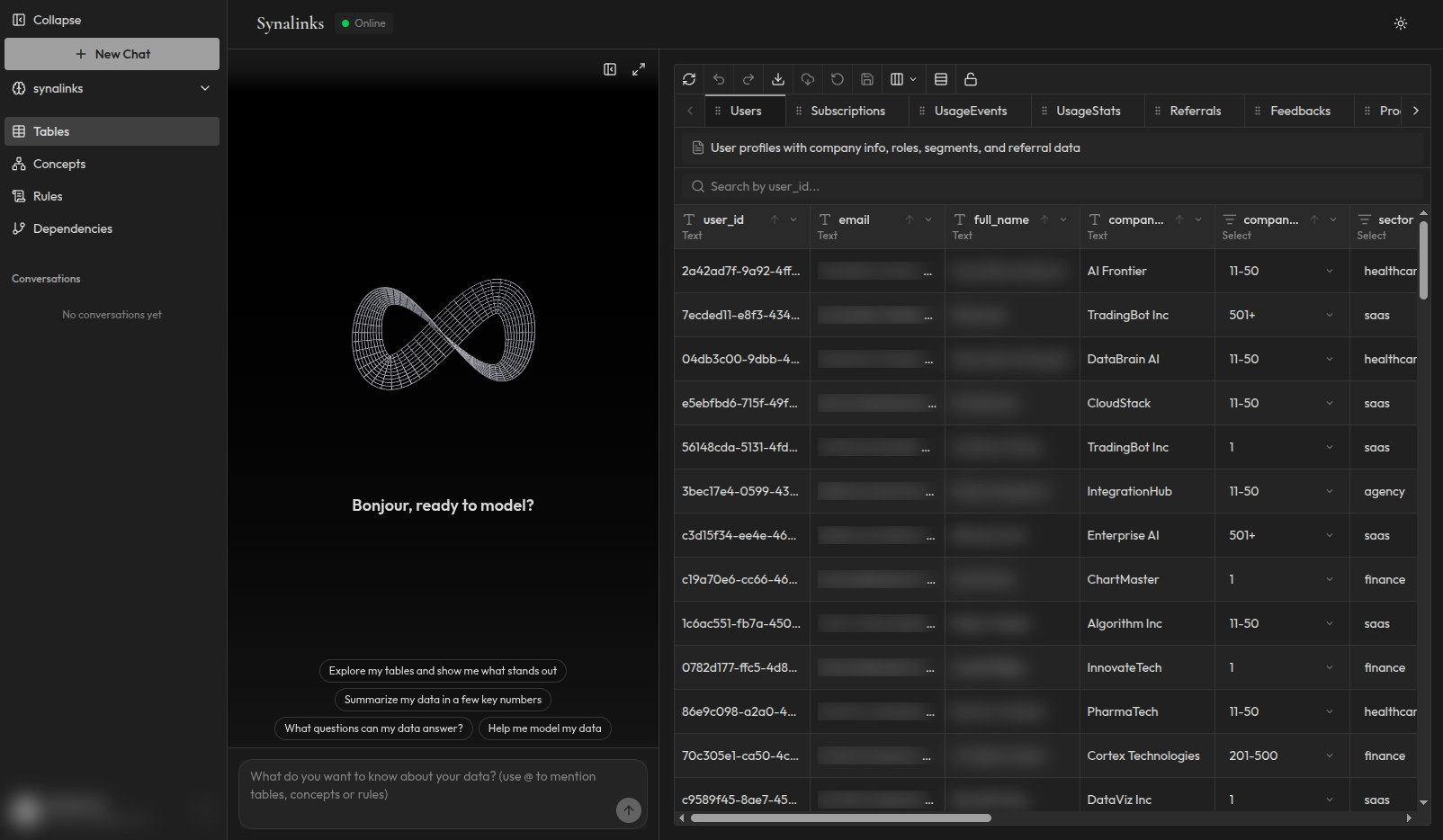
- Décrivez votre domaine. Indiquez au système ce qui compte : vos règles métier, vos définitions, votre logique spécifique au domaine. Ceux-ci deviennent les règles de raisonnement.
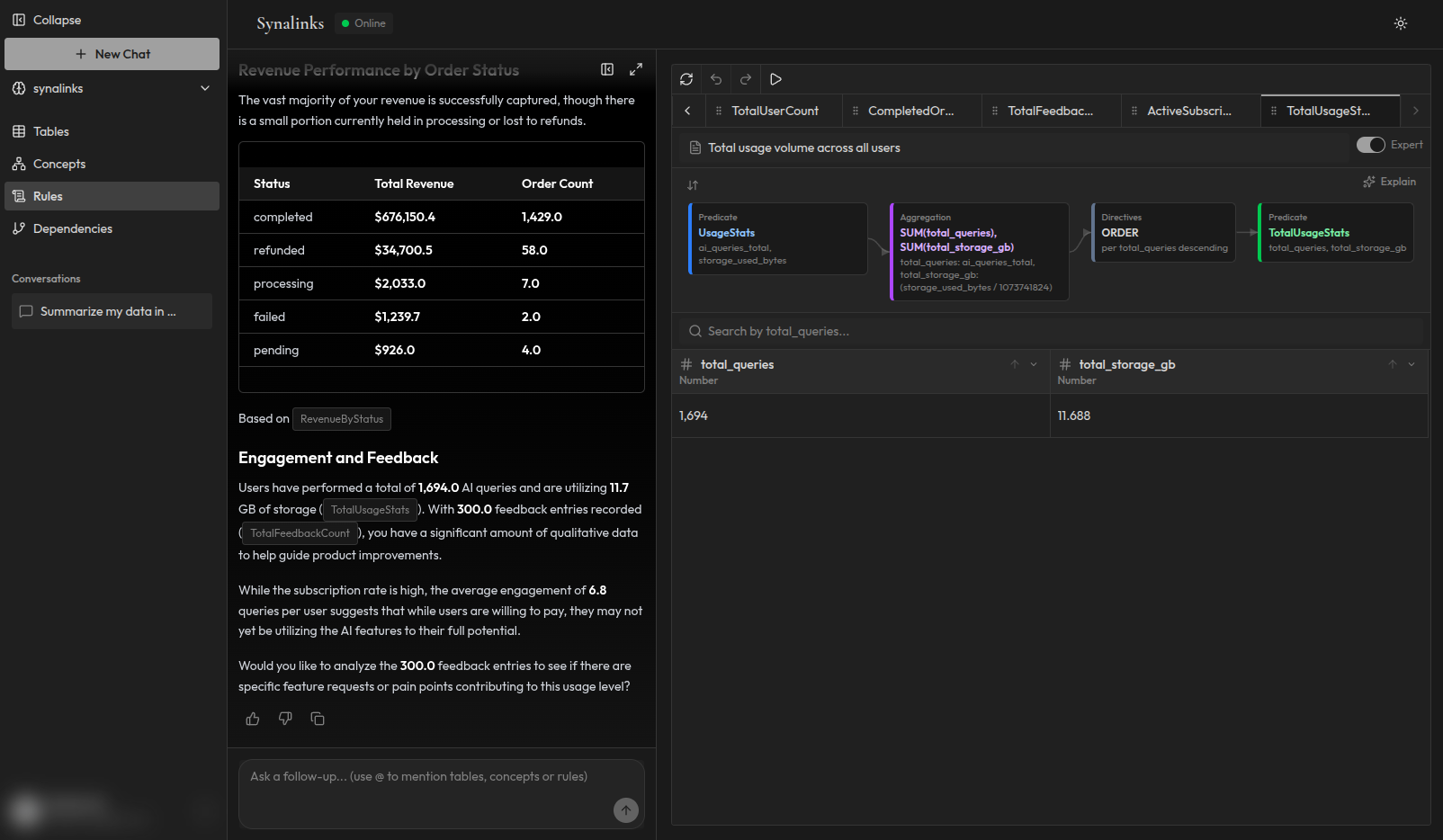
- Interrogez de manière déterministe. Vos agents appellent l'API Synalinks Memory. Chaque requête retourne une réponse déduite avec une chaîne de raisonnement complète. Même question, mêmes données, même réponse.
Pas d'embeddings. Pas de recherche vectorielle. Pas d'espoir que le modèle de langage interprète correctement le contexte récupéré.
Pour commencer
Si vous construisez des agents IA qui doivent être fiables, traçables et cohérents, une couche de raisonnement déterministe est la pièce architecturale qui vous manque.
Synalinks Memory est disponible à partir de 49 €/mois. Connectez une source de données, définissez quelques règles, et observez le raisonnement déterministe en action.
Les captures d'écran sont fournies à titre illustratif. Le produit final peut différer sur certains aspects. Les données présentées sont synthétiques et utilisées uniquement à des fins de démonstration.