Pourquoi les agents IA échouent à la couche mémoire
Équipe Synalinks
Pourquoi les agents IA échouent à la couche mémoire
La démo a marché. Le pilote s'est bien passé. Les stakeholders étaient impressionnés. Puis vous avez mis en production.
Maintenant l'agent donne des réponses différentes à la même question selon l'heure de la journée. Il cite avec assurance des données mises à jour il y a deux semaines. Il ne peut pas expliquer comment il est arrivé à une conclusion. Votre équipe support passe plus de temps à vérifier les réponses de l'agent qu'elle n'en aurait passé à faire le travail manuellement.
Cette histoire se répète dans toute l'industrie. La majorité des implémentations RAG en entreprise peinent à dépasser leur première année. Peu d'organisations réussissent à scaler leurs agents IA au-delà du pilote. Et la cause principale, citée post-mortem après post-mortem, remonte à la même racine : la couche mémoire.
Pas le modèle. Pas les prompts. La mémoire.
Les trois modes de défaillance
Quand nous parlons de « couche mémoire », nous désignons le système qui stocke, récupère et fournit du contexte à l'agent IA. Dans la plupart des architectures actuelles, c'est une base de données vectorielle avec un pipeline RAG. Et elle échoue de trois manières prévisibles.
1. Contexte obsolète
Les bases de données vectorielles stockent des instantanés. Quand vos données sources changent, vos embeddings ne se mettent pas automatiquement à jour. Selon votre pipeline d'ingestion, il peut y avoir des heures ou des jours de décalage entre un changement de données et son reflet dans le contexte de l'agent.
Pour un agent de support client, cela signifie citer un plan tarifaire déprécié la semaine dernière. Pour un agent d'analytics, cela signifie raisonner sur les chiffres du mois dernier quand ceux de ce mois sont disponibles. L'agent ne sait pas que son contexte est obsolète. Il présente des informations périmées avec une confiance totale.
2. Données contradictoires
La recherche par similarité vectorielle retourne les top-k fragments les plus similaires. Mais « le plus similaire » ne signifie pas « le plus pertinent », et certainement pas « mutuellement cohérent ».
Quand votre base de connaissances contient plusieurs versions d'un document de politique, ou quand un point de données apparaît dans différents contextes avec différentes valeurs, le modèle de langage reçoit des informations contradictoires. Il doit résoudre le conflit seul, sans règles explicites sur quelle source a la priorité. Parfois il choisit la bonne. Parfois non. Parfois il les fusionne en quelque chose qui n'a jamais existé.
3. Absence de chaîne de raisonnement
Quand l'agent produit une réponse, vous pouvez voir la sortie finale. Vous pouvez même voir quels documents ont été récupérés. Mais vous ne pouvez pas voir le raisonnement qui a connecté les documents récupérés à la conclusion.
Cela rend le débogage quasi impossible. La réponse était-elle fausse parce que les mauvais documents ont été récupérés ? Parce que les bons documents ont été récupérés mais mal interprétés ? Parce que le modèle a halluciné une relation qui n'existe pas dans les données ? Sans chaîne de raisonnement, vous devinez.
Et dans les industries réglementées, « nous ne savons pas comment l'agent est arrivé à cette réponse » n'est pas acceptable.
Pourquoi de meilleurs prompts ne résolvent pas le problème
Le réflexe, quand un agent produit de mauvaises réponses, est de corriger les prompts. Ajouter plus d'instructions. Inclure des exemples. Dire au modèle de « n'utiliser que le contexte fourni ».
Cela aide à la marge, mais ne traite pas le problème structurel. Le problème n'est pas que le modèle ignore ses instructions. Le problème est que la couche mémoire lui fournit de mauvaises entrées : des données obsolètes, des fragments contradictoires, des relations non structurées qui nécessitent un raisonnement pour lequel le modèle n'est pas conçu.
L'ingénierie de prompts est une optimisation par-dessus un système fondamentalement probabiliste. Quand vous avez besoin de fiabilité déterministe, il faut changer le système, pas ajuster les paramètres.
À quoi ressemble une couche mémoire structurée
L'alternative est d'arrêter de traiter la mémoire comme un problème de recherche et de commencer à la traiter comme un problème de connaissance.
Une couche mémoire structurée organise vos données en concepts, relations et règles vérifiés avant que l'agent ne les voie. Au lieu d'encoder des documents en vecteurs en espérant que la recherche par similarité trouve les bons fragments, vous construisez un graphe de connaissances où :
- Les entités sont typées et ont des propriétés définies
- Les relations entre entités sont explicites et vérifiées
- Les règles métier sont encodées comme de la logique de premier ordre, pas enfouies dans des instructions de prompt
- Les changements temporels sont suivis, pour que le système sache ce qui est actuel
Quand un agent interroge ce type de mémoire, il ne reçoit pas « les 5 fragments de texte les plus similaires ». Il reçoit une réponse déduite, produite en appliquant des règles définies à des connaissances vérifiées. La chaîne de raisonnement est capturée à chaque étape. La réponse est déterministe.
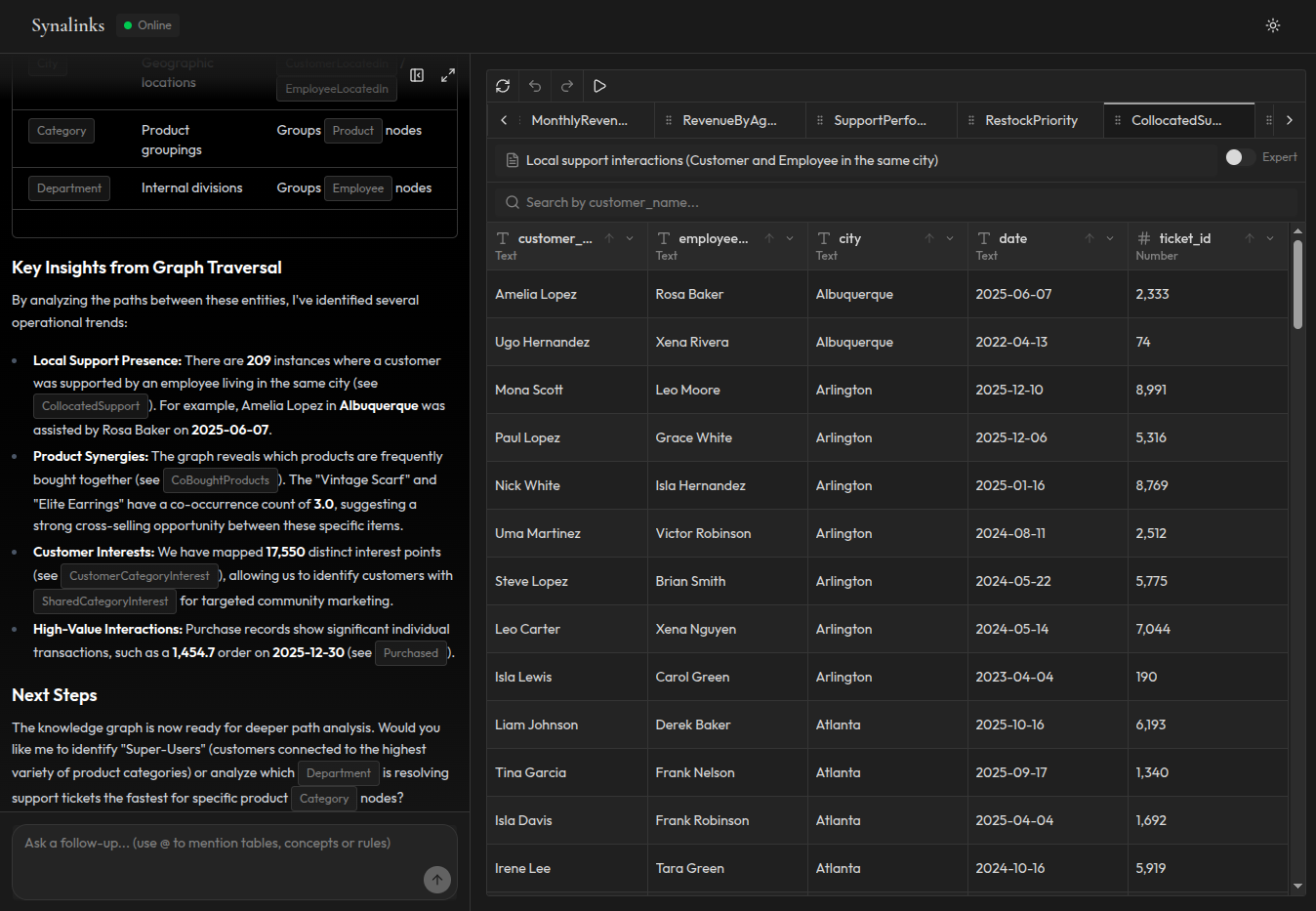
Le fossé de fiabilité en production
La différence entre un agent de démo et un agent de production n'est ni le modèle ni les prompts. C'est le contrat de fiabilité.
Un agent de démo doit être impressionnant. Il doit produire des réponses plausibles qui font hocher la tête aux stakeholders. Le RAG vectoriel est parfait pour cela. Il récupère du contexte qui semble pertinent et le modèle génère une réponse qui sonne bien.
Un agent de production doit être correct. Il doit produire la même réponse pour la même question, à chaque fois. Il doit expliquer comment il est arrivé à cette réponse. Il doit refléter l'état actuel des données, pas un instantané en cache. Et quand il n'a pas assez d'informations pour répondre de manière fiable, il doit le dire au lieu de deviner.
C'est ce fossé que la mémoire structurée comble.
Comment Synalinks Memory résout ce problème
Synalinks Memory est une couche mémoire structurée pour les agents IA. Elle traite chacun des trois modes de défaillance :
Contexte obsolète : Les connaissances sont structurées à partir de vos sources de données en temps réel. Quand les données changent, le graphe de connaissances le reflète. Votre agent raisonne toujours sur des informations actuelles.
Données contradictoires : Il n'y a pas de fragments contradictoires parce qu'il n'y a pas de fragments. Les connaissances sont organisées en concepts vérifiés avec des relations explicites. Il y a une source de vérité unique, pas cinq morceaux de texte qui se ressemblent.
Absence de chaîne de raisonnement : Chaque réponse est accompagnée d'une trace complète : quelles règles ont été appliquées, quels points de données ont été utilisés, et comment la conclusion a été déduite. Quand quelque chose semble faux, vous pouvez identifier exactement où et pourquoi.
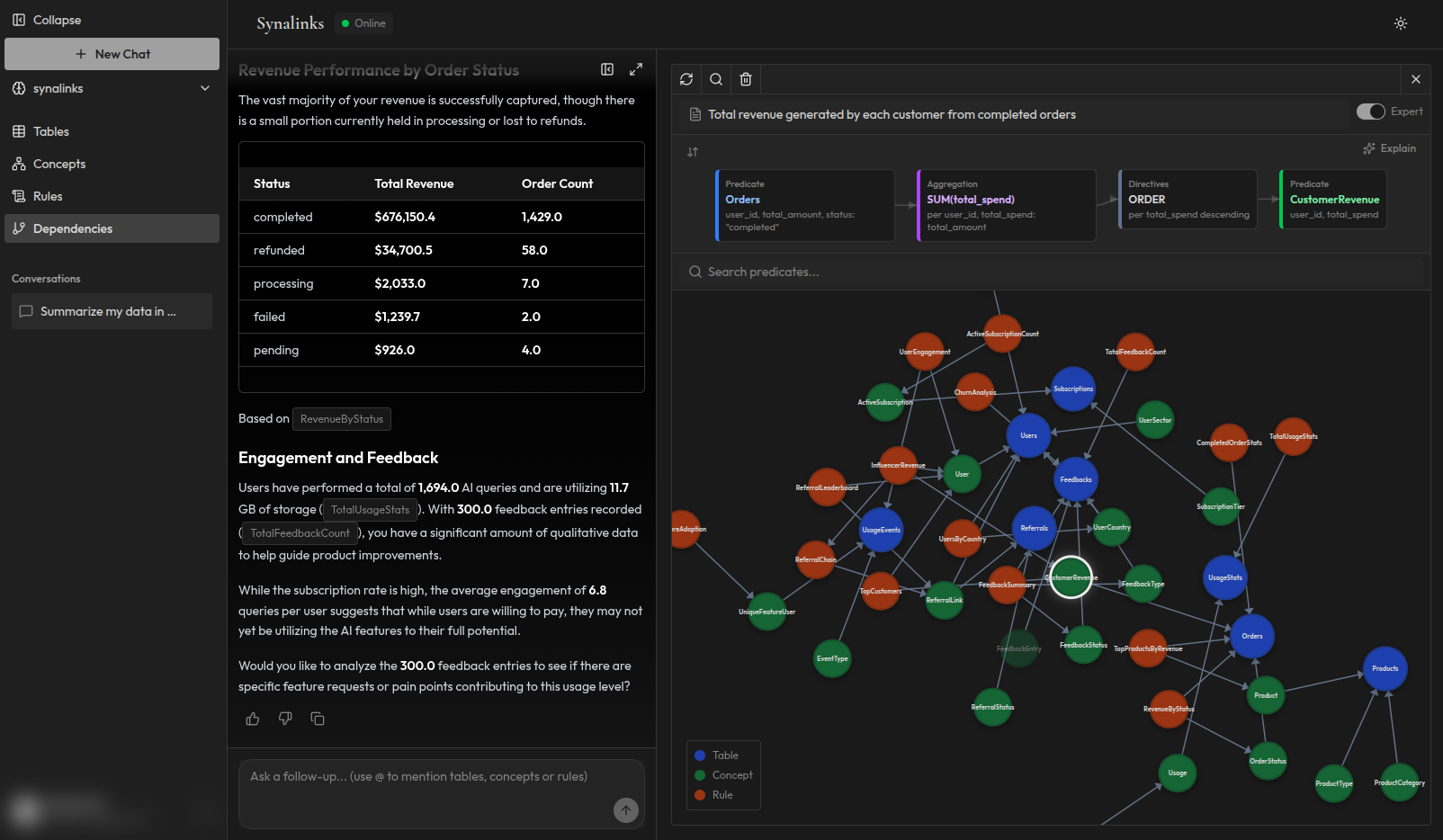
Le résultat : vos agents donnent la même réponse à la même question à chaque fois, ils peuvent expliquer comment ils y sont arrivés, et ils travaillent avec les données telles qu'elles existent maintenant.
Passer du pilote à la production
Si votre agent IA fonctionne en démo mais échoue en production, le problème est presque certainement dans la couche mémoire. De meilleurs modèles et de meilleurs prompts sont des améliorations incrémentales d'un système qui a une faiblesse structurelle.
Une couche mémoire structurée est le changement architectural qui fait passer votre agent de « fonctionne la plupart du temps » à « fonctionne à chaque fois, et voici la preuve ».
Synalinks Memory est disponible à partir de 49 €/mois. Connectez vos données, définissez vos règles, et voyez à quoi ressemble une mémoire d'agent IA de niveau production.
Les captures d'écran sont fournies à titre illustratif. Le produit final peut différer sur certains aspects. Les données présentées sont synthétiques et utilisées uniquement à des fins de démonstration.