Build an AI Agent That Never Hallucinates
Synalinks Team
How to Build an AI Agent That Never Hallucinates on Your Domain Data
"Never" is a strong word in AI. But when it comes to your own domain data, the facts you've verified, the rules you've defined, the relationships you know to be true, hallucination isn't an inevitability. It's an architectural choice.
Most AI agents hallucinate because they're asked to reason over unstructured text. The language model receives a pile of retrieved document chunks and has to figure out what's true, what's relevant, and how the pieces connect. That's where errors creep in.
The fix isn't better prompts or lower temperature settings. It's removing the opportunity for hallucination entirely: give the agent structured, verified knowledge and let the reasoning happen through rules, not token prediction.
Understanding why hallucinations happen
Hallucinations aren't random. They follow three predictable patterns:
Pattern 1: The model fills gaps with plausible fiction
When the retrieved context doesn't contain a complete answer, the language model doesn't say "I don't know." It generates something plausible. If your knowledge base has the customer's plan type and their last login date but not their renewal date, the model might infer one based on patterns it learned during training. That inference might be wrong.
Pattern 2: The model misreads relationships
"Company A acquired Company B in 2023" and "Company B is a subsidiary of Company C" might both appear in retrieved chunks. The model might conclude that Company A acquired a subsidiary of Company C, when in reality Company B was independent at the time of acquisition. The relationships are temporal and contextual, but the model treats the chunks as flat, atemporal text.
Pattern 3: The model blends contradictory sources
When multiple chunks contain different values for the same data point (a price that changed, a policy that was updated), the model has to choose. Sometimes it picks the wrong version. Sometimes it averages them. Sometimes it generates a value that appears in neither source.
All three patterns share a root cause: the model is doing reasoning it wasn't designed to do, over data that isn't structured for reasoning.
The structured knowledge approach
The principle is simple: if you don't want the model to guess, don't give it anything to guess about.
Instead of retrieving text chunks and hoping the model interprets them correctly, you structure your domain knowledge into three layers:
Layer 1: Verified facts
Every data point in the system is a typed, verified fact. A patient has a name, a date of birth, a medical history, and a list of appointments. These aren't text fragments pulled from documents. They're structured records with defined schemas.
When a fact isn't available, the system knows it's missing. There's no gap for the model to fill with plausible fiction.
Layer 2: Explicit relationships
The connections between entities are first-class objects. Patient A has appointment with Doctor B. Doctor B works in Department C. Patient A received Treatment D. These relationships are typed, directional, and verified.
When the agent needs to answer a question that spans multiple entities, it follows the explicit relationships. It doesn't have to infer connections from text proximity or embedding similarity.
Layer 3: Domain rules
Domain logic is encoded as rules, not prompt instructions. "Frequent patient" means more than 10 appointments in the past year. "High workload" means a doctor with more than 200 appointments per quarter. "Follow-up required" is determined by treatment type and days since last visit.
These rules are applied deterministically. The model doesn't have to figure out what "frequent patient" means from context clues in the retrieved documents. The system already knows.
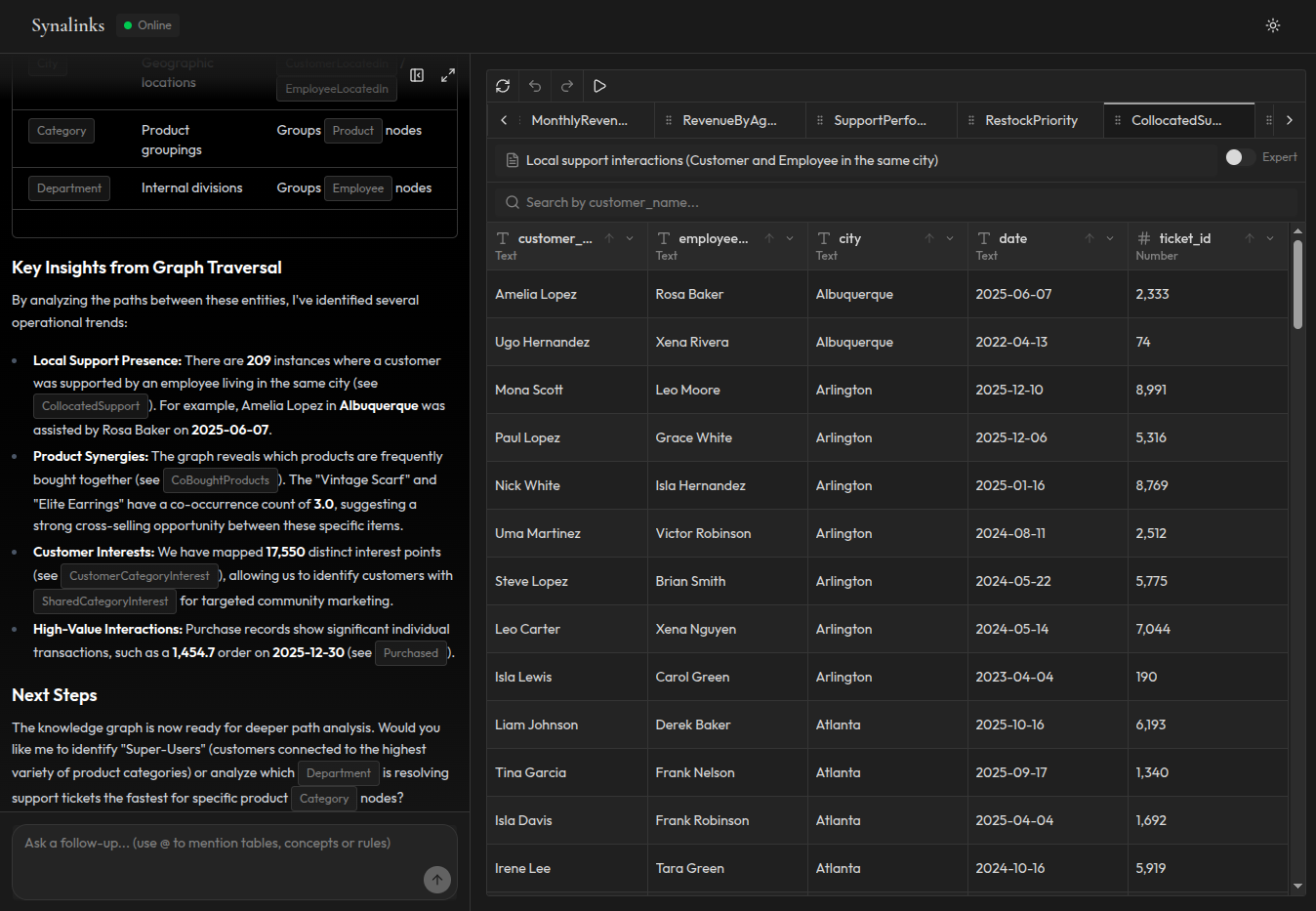
What changes in the agent's architecture
With structured knowledge in place, the agent's memory architecture changes fundamentally:
Before (RAG):
- User asks a question
- Question is embedded and similar chunks are retrieved
- Chunks + question go to the language model
- Model generates an answer (might hallucinate)
After (structured knowledge):
- User asks a question
- Question is parsed into a structured query
- The reasoning engine applies rules to verified facts and relationships
- A derived answer with full reasoning chain is produced
- The language model formats the answer in natural language
The critical difference: in step 4 of the RAG flow, the model is reasoning. In step 5 of the structured flow, the model is only formatting. The reasoning already happened deterministically.
The model can still hallucinate in the formatting step, but the scope is limited to presentation, not substance. It might phrase things awkwardly, but it can't invent facts that aren't in the derived result.
Practical example: healthcare analytics agent
Let's make this concrete. You're building an agent that answers questions about patient data for a healthcare system.
The question: "Which patients have the highest number of appointments?"
RAG approach: The system retrieves chunks about patient records and appointment logs. The model reads both and tries to count appointments per patient. Maybe some appointments are missing from the retrieved chunks, or the model miscounts because appointment records span multiple documents. It might still give an answer. It doesn't know what it doesn't know.
Structured knowledge approach: The system has each patient as an entity with verified appointment relationships through HasAppointmentEdge. The reasoning engine traverses the graph, counts appointments per patient, and ranks them: Hana Dubois (16 appointments), Hugo Rosso (15), Clara Martin (14). The reasoning chain shows exactly which relationships and which data produced the conclusion.
No hallucination is possible here. The answer is derived, not generated. If appointment data is missing for a patient, the system flags it explicitly instead of guessing.
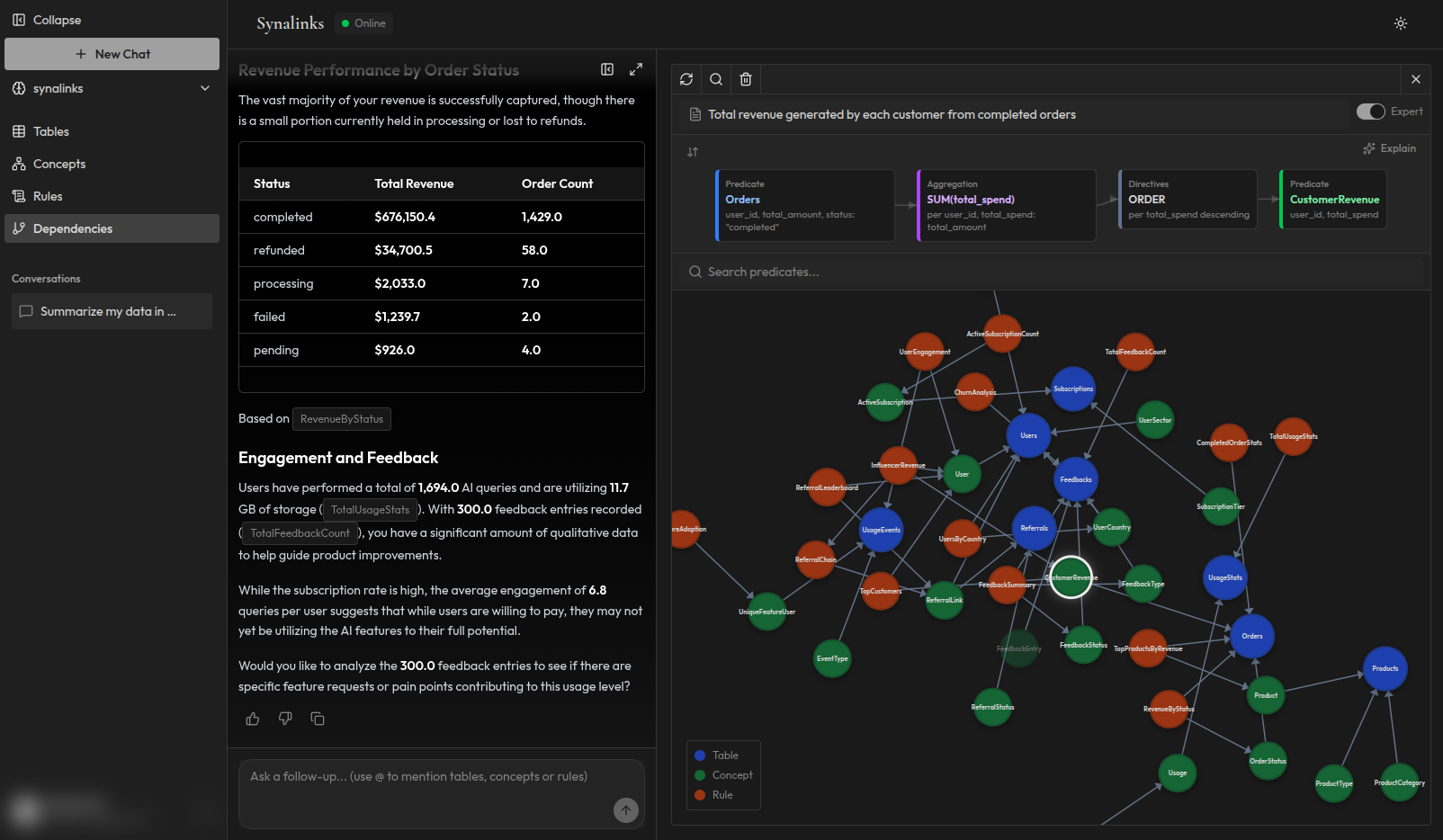
The key insight: everything can be a rule
A common misconception is that open-ended questions like "What patterns are you seeing in patient visits?" can't be answered deterministically. But if the pattern analysis is encoded as a rule in your structured knowledge, the answer is derived, not generated, and hallucination is eliminated just the same.
The strategy is to maximize the scope of structured knowledge by encoding as much domain logic as possible into rules: appointment frequency metrics, department workload analysis, treatment outcome thresholds, and clinical decision criteria. The more you encode, the more questions your agent answers deterministically with full traceability.
Getting started with Synalinks Memory
Synalinks Memory implements the structured knowledge approach described in this article. It gives your AI agents a layer of verified facts, explicit relationships, and domain rules to reason over deterministically.
- Connect your data sources (databases, spreadsheets, files, APIs)
- Describe your domain (entities, relationships, business rules)
- Query deterministically (every answer comes with a full reasoning chain)
Your agent stops guessing and starts deriving. For your domain data, hallucination becomes structurally impossible.
Screenshots are provided for illustration purposes. The final product may differ in some aspects. All data shown is synthetic and used for demonstration purposes only.