RAG vs Knowledge Graphs: A Developer's Decision Guide
Synalinks Team
RAG vs Knowledge Graphs: A Developer's Decision Guide
You're building an AI agent and you need to give it access to your company's data. The default answer has been RAG: embed your documents, store them in a vector database, and retrieve relevant chunks at query time. Simple, fast, well-documented.
But as teams move agents from prototypes to production, a different architecture keeps coming up: knowledge graphs. And the results are hard to ignore. Knowledge graph-based approaches consistently outperform vector RAG on accuracy in structured domains.
So which do you actually need? The answer depends on your data, your questions, and your reliability requirements.
How vector RAG works
Vector RAG follows a straightforward pipeline:
- Ingest: Take your documents (PDFs, web pages, database exports) and split them into chunks
- Embed: Convert each chunk into a vector using an embedding model
- Store: Save the vectors in a vector database (Pinecone, Weaviate, Qdrant, pgvector, etc.)
- Retrieve: When a query comes in, embed it, find the top-k most similar chunks
- Generate: Pass the retrieved chunks + query to a language model to produce an answer
Strengths:
- Fast to set up. You can have a working prototype in an afternoon
- Works well with unstructured text (articles, documentation, emails)
- Scales horizontally: more data just means more vectors
- Large ecosystem of tools and tutorials
Weaknesses:
- Similarity isn't relevance. The most similar chunk isn't always the most useful one
- No understanding of relationships between entities
- Contradictory chunks get retrieved without resolution
- No reasoning chain: you can see what was retrieved but not how it was interpreted
- Accuracy degrades as the knowledge base grows and similar-looking chunks multiply, leading to AI agent hallucinations
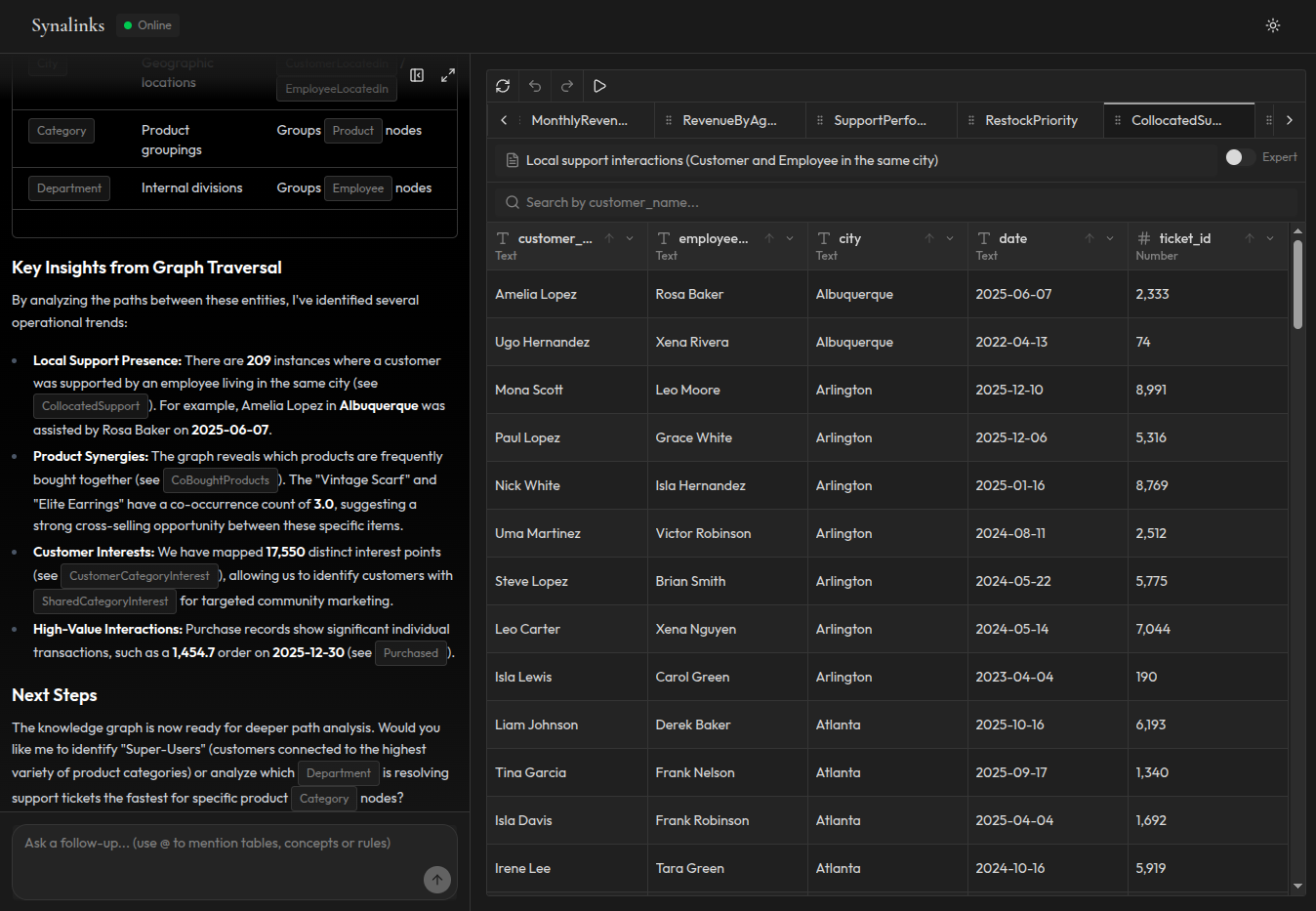
How knowledge graphs work
Knowledge graphs take a fundamentally different approach. Instead of storing text as vectors, they model your data as entities and relationships:
- Model: Define the types of entities in your domain (customers, orders, products) and their relationships
- Extract: Populate the graph from your data sources, either manually, through ETL, or with automated extraction
- Verify: Validate that the extracted knowledge is accurate and consistent
- Reason: Apply rules and traversals to answer questions by following explicit relationships
- Present: Format the derived answer for the user
Strengths:
- Explicit relationships between entities: the system knows that Customer A placed Order B which contains Product C
- Multi-hop reasoning: questions that require following chains of relationships work naturally
- Deterministic: the same query over the same graph produces the same result
- Traceable: every answer can be explained by showing the path through the graph
- Handles temporal data: you can model when things changed and reason over time
Weaknesses:
- More upfront work to model the domain and define the schema
- Less flexible with purely unstructured, free-form text
- Requires thought about what entities and relationships matter
- Smaller ecosystem compared to vector RAG
Where knowledge graphs outperform RAG
The difference becomes clear when you look at the types of questions production agents actually face:
- Structured queries: "Which patients have more than 10 appointments this year?" This requires following explicit relationships, not similarity matching
- Multi-hop reasoning: "Which doctors in the Cardiology department have the highest patient load?" Vector RAG accuracy drops sharply when answers require connecting multiple pieces of information. Knowledge graphs handle this natively
- Temporal questions: "Show me all appointments for Dr. Chen in the past 90 days." You need reasoning over time, not text similarity
These are relationship and reasoning questions. They aren't similarity questions.
When to use vector RAG
Vector RAG is the right choice when:
- Your data is primarily unstructured text (documentation, articles, research papers) and the questions are about finding relevant information within that text
- You need a working prototype fast and accuracy requirements are moderate
- Questions are single-hop: the answer exists in a single chunk and doesn't require connecting multiple pieces of information
- The use case is exploratory: users are searching for information, not expecting precise, verifiable answers
- Your data doesn't have strong relational structure: there aren't meaningful entity-to-entity relationships to model
Good fits: documentation search, research assistant, FAQ bot, content recommendation.
When to use a knowledge graph
A knowledge graph is the right choice when:
- Accuracy matters more than speed-to-prototype. Wrong answers have real consequences
- Questions involve relationships. "Which patients are treated by doctors in a specific department?" can't be answered by similarity search
- You need deterministic, repeatable answers. The same question must produce the same answer every time
- Auditability is required. You need to show stakeholders (or regulators) exactly how the agent reached its conclusion
- Your data has relational structure: patients, doctors, appointments, treatments, departments, and the connections between them
- Temporal reasoning matters: you need to know not just what's true now, but what was true when
Good fits: healthcare analytics agents, compliance systems, operational decision support, anything where "probably right" isn't good enough. See also our guide on AI agent memory architecture to understand how knowledge graphs fit into the broader memory stack.
The hybrid approach: GraphRAG
A middle ground is emerging: GraphRAG. This approach uses a knowledge graph as the primary source of truth for structured data, while keeping vector RAG for unstructured content that doesn't fit neatly into a graph.
The idea is straightforward: use the right tool for each type of data. Structured relationships go into the graph. Free-form documents get embedded as vectors. The agent queries both and the results are combined.
This works, but it adds architectural complexity. You now have two retrieval systems to maintain, two sets of data pipelines, and the challenge of reconciling answers that come from different sources.
What Synalinks Memory offers
Synalinks Memory takes the knowledge graph approach and removes the parts that make it hard.
You don't need to manually design a schema. Connect your data sources and Synalinks automatically extracts entities, relationships, and rules. You describe your domain in natural terms ("these are customers, these are orders, overdue means more than 30 days past due") and the system structures the knowledge accordingly.
You don't need to choose between structured and unstructured. Synalinks processes both, structuring what it can and preserving what it can't.
And you get the key benefits of a knowledge graph without the typical overhead:
- Deterministic answers with full reasoning chains
- Automatic knowledge extraction from your data sources
- Temporal reasoning out of the box
- A simple API your agents can call
If you're hitting the accuracy ceiling of vector RAG and considering a knowledge graph, Synalinks Memory is the fastest path from "we need structured knowledge" to "it's running in production."
Screenshots are provided for illustration purposes. The final product may differ in some aspects. All data shown is synthetic and used for demonstration purposes only.