Why AI Agent Failures Start at the Memory Layer
Synalinks Team
Why AI Agent Failures Start at the Memory Layer
The demo worked. The pilot went well. Stakeholders were impressed. Then you shipped to production.
Now the agent gives different answers to the same question depending on the time of day. It confidently cites data that was updated two weeks ago. It can't explain how it reached a conclusion. Your support team is spending more time verifying the agent's outputs than they would have spent doing the work manually.
This story plays out across the industry. The majority of enterprise RAG implementations struggle to move past their first year. Few organizations successfully scale their AI agents beyond the pilot stage. And the leading cause, cited in post-mortem after post-mortem, traces back to the same root: the memory layer.
Not the model. Not the prompts. The memory.
The three failure modes
When we say "memory layer," we mean the system that stores, retrieves, and provides context to the AI agent. In most architectures today, this is a vector database with a RAG pipeline. And it fails in three predictable ways.
1. Stale context
Vector databases store snapshots. When your source data changes, your embeddings don't automatically update. Depending on your ingestion pipeline, there can be hours or days of lag between a data change and its reflection in the agent's context.
For a customer support agent, this means citing a pricing plan that was deprecated last week. For an analytics agent, this means reasoning over last month's numbers when this month's are available. The agent doesn't know its context is stale. It presents outdated information with full confidence.
2. Conflicting retrievals
Vector similarity search returns the top-k most similar chunks. But "most similar" doesn't mean "most relevant," and it definitely doesn't mean "mutually consistent."
When your knowledge base contains multiple versions of a policy document, or when a data point appears in different contexts with different values, the language model receives contradictory information. It has to reconcile the conflict on its own, with no explicit rules about which source takes precedence. Sometimes it picks the right one. Sometimes it doesn't. Sometimes it blends them into something that never existed.
3. No reasoning chain
When the agent produces an answer, you can see the final output. You can even see which documents were retrieved. But you can't see the reasoning that connected the retrieved documents to the conclusion.
This makes debugging nearly impossible. Was the answer wrong because the wrong documents were retrieved? Because the right documents were retrieved but misinterpreted? Because the model hallucinated a relationship that doesn't exist in the data? Without a reasoning chain, you're guessing.
And in regulated industries, "we're not sure how the agent reached that answer" isn't acceptable.
Why better prompts don't fix this
The instinct, when an agent produces wrong answers, is to fix the prompts. Add more instructions. Include examples. Tell the model to "only use the provided context."
This helps at the margins, but it doesn't address the structural issue. The problem isn't that the model is ignoring its instructions. The problem is that the memory layer is giving it bad inputs: stale data, contradictory chunks, unstructured relationships that require reasoning the model wasn't designed to do.
Prompt engineering is an optimization on top of a fundamentally probabilistic system. When you need deterministic reliability, you need to change the system, not tune the parameters.
What a structured memory layer looks like
The alternative is to stop treating memory as a retrieval problem and start treating it as a knowledge problem.
A structured memory layer organizes your data into verified concepts, relationships, and rules before the agent ever sees it. Instead of embedding documents as vectors and hoping similarity search finds the right chunks, you build a knowledge graph where:
- Entities are typed and have defined properties
- Relationships between entities are explicit and verified
- Business rules are encoded as first-class logic, not buried in prompt instructions
- Temporal changes are tracked, so the system knows what's current
When an agent queries this kind of memory, it doesn't get "the 5 most similar text chunks." It gets a derived answer, produced by applying defined rules to verified knowledge. The reasoning chain is captured at every step. The answer is deterministic.
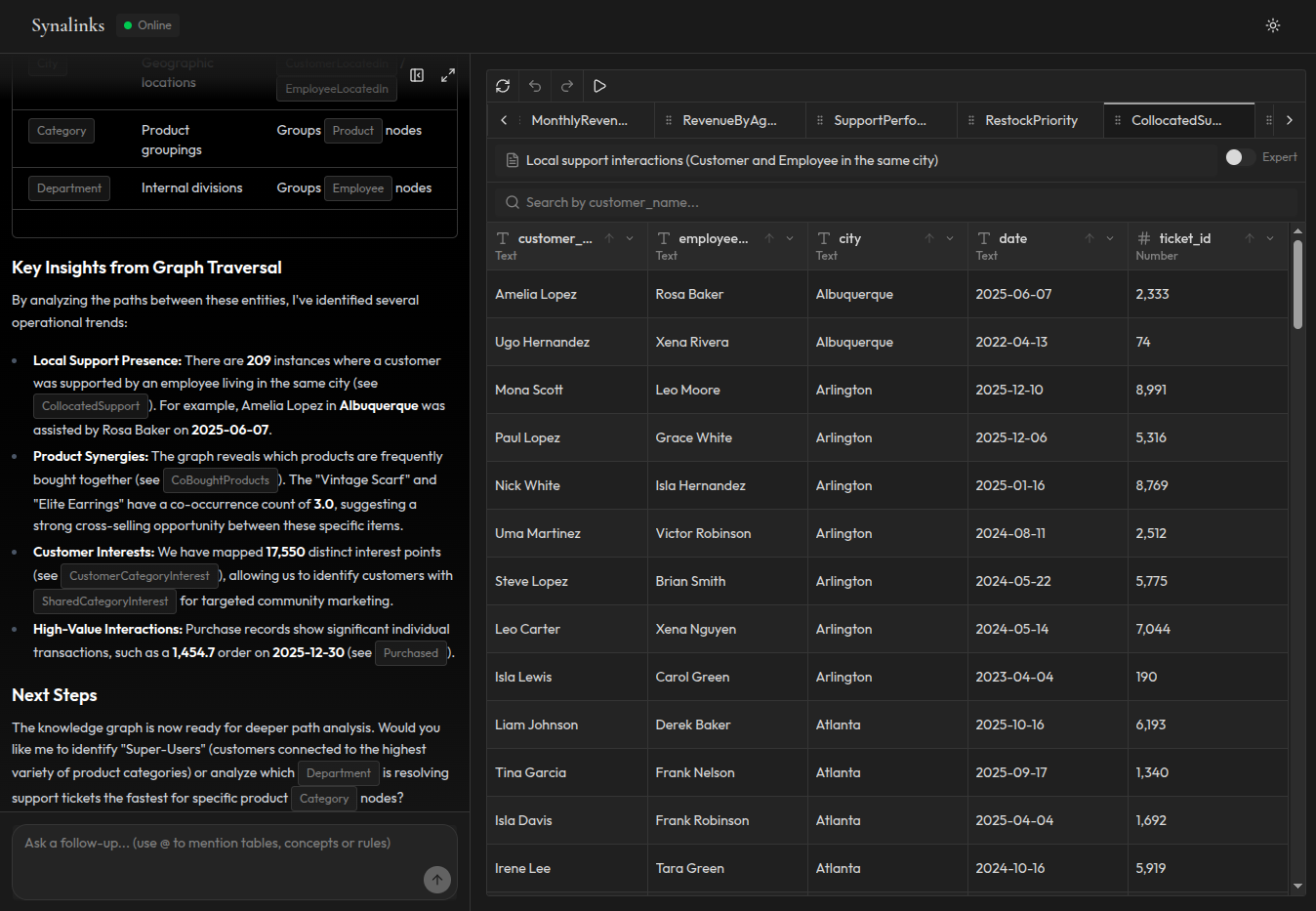
The production reliability gap
The difference between a demo agent and a production agent isn't the model or the prompts. It's the reliability contract.
A demo agent needs to be impressive. It needs to produce plausible answers that make stakeholders nod. Vector RAG is perfect for this. It retrieves relevant-looking context and the model generates a confident-sounding response.
A production agent needs to be correct. It needs to produce the same answer for the same question, every time. It needs to explain how it reached that answer. It needs to reflect the current state of the data, not a cached snapshot. And when it doesn't have enough information to answer reliably, it needs to say so instead of guessing.
This is the gap that structured memory closes.
How Synalinks Memory solves this
Synalinks Memory is a structured memory layer for AI agents. It addresses each of the three failure modes:
Stale context: Knowledge is structured from your live data sources. When data changes, the knowledge graph reflects it. Your agent always reasons over current information.
Conflicting retrievals: There are no conflicting chunks because there are no chunks. Knowledge is organized into verified concepts with explicit relationships. There's one source of truth, not five similar-looking text fragments.
No reasoning chain: Every answer comes with a complete trace: which rules were applied, which data points were used, and how the conclusion was derived. When something looks wrong, you can pinpoint exactly where and why.
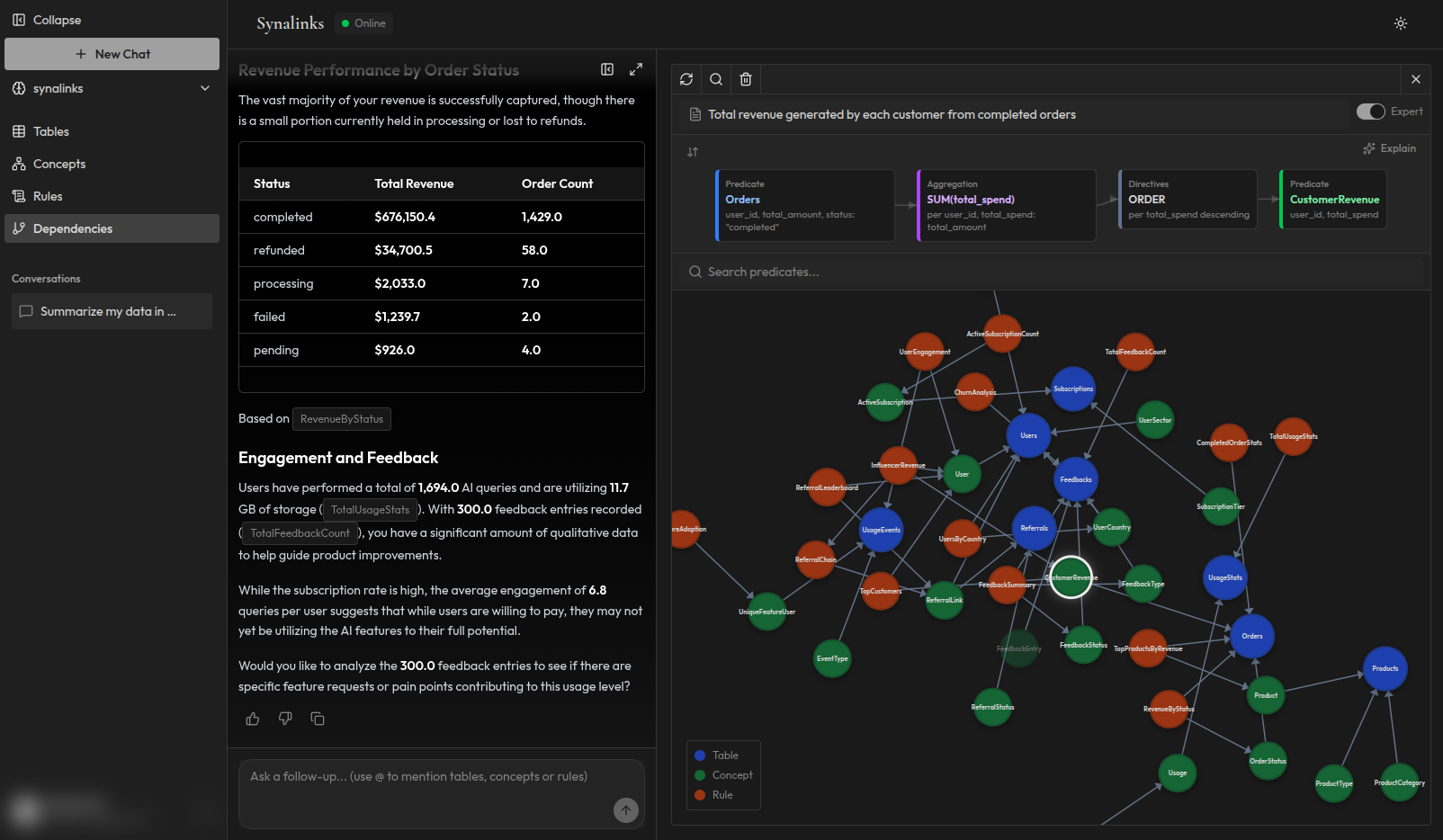
The result: your agents give the same answer to the same question every time, they can explain how they got there, and they work with the data as it exists right now.
Moving from pilot to production
If your AI agent works in demos but fails in production, the problem is almost certainly in the memory layer. Better models and better prompts are incremental improvements to a system that has a structural weakness.
A structured memory layer is the architectural change that moves your agent from "works most of the time" to "works every time, and here's proof."
Synalinks Memory is available starting at €49/month. Connect your data, define your rules, and see what production-grade AI agent memory looks like.
Screenshots are provided for illustration purposes. The final product may differ in some aspects. All data shown is synthetic and used for demonstration purposes only.