Mémoire des agents IA : court terme, long terme et structurée
Équipe Synalinks
Architecture mémoire des agents IA : court terme, long terme et connaissances structurées
Chaque agent IA a un problème de mémoire. Le modèle de langage qui le propulse n'a pas d'état persistant. Chaque requête repart de zéro. Sans système de mémoire externe, votre agent ne peut pas se souvenir de ce qui s'est passé il y a cinq minutes, encore moins raisonner sur des mois de connaissances accumulées.
L'écosystème des frameworks d'agents a répondu avec une variété de solutions de mémoire : buffers d'historique de chat, stores vectoriels, caches clé-valeur, et plus récemment, graphes de connaissances. Mais ceux-ci ne sont pas interchangeables. Ils résolvent des problèmes différents, et la plupart des agents en production en nécessitent plus d'un.
Ce guide décompose les trois couches de mémoire d'agent, ce que chacune fait, où les outils actuels échouent, et comment construire une architecture qui fonctionne vraiment à l'échelle.
Couche 1 : Mémoire à court terme (contexte de conversation)
La mémoire à court terme garde la trace de l'interaction en cours. C'est la raison pour laquelle votre agent sait à quoi « il » fait référence quand vous posez une question de suivi.
Comment ça marche : L'implémentation la plus courante est un buffer d'historique de chat. Chaque message de la conversation est stocké et passé au modèle de langage comme contexte à chaque requête suivante. Certains frameworks (LangChain, LangGraph) proposent des buffers à fenêtre glissante qui gardent les N derniers messages, ou des buffers de résumé qui condensent les anciens messages.
Ce que ça résout :
- Conversations multi-tours où le contexte se transmet
- Questions de suivi qui font référence à des parties antérieures de la conversation
- Continuité de tâche au sein d'une même session
Où ça échoue :
- La mémoire est perdue quand la session se termine
- Les limites de fenêtre de contexte plafonnent la quantité d'historique incluable
- Aucun mécanisme pour retenir des faits importants entre les sessions
- La synthèse perd du détail : le résumé d'une conversation de 20 messages ne préserve pas chaque donnée discutée
La mémoire à court terme est un problème résolu pour la plupart des cas. Si votre agent ne gère que des conversations en session unique, un buffer d'historique suffit.
Couche 2 : Mémoire à long terme (rappel persistant)
La mémoire à long terme permet à l'agent de se souvenir d'informations entre les sessions. Un agent customer success devrait se rappeler que le Client X préfère la communication par email et a eu un problème de facturation le trimestre dernier, même si ces faits sont apparus il y a des semaines.
Comment ça marche : L'approche typique est de stocker les faits importants dans une base vectorielle ou un store clé-valeur. Après chaque conversation, les informations pertinentes sont extraites et encodées. Lors des requêtes futures, le système récupère les souvenirs stockés qui sont sémantiquement similaires à la requête en cours.
Ce que ça résout :
- Continuité inter-sessions : l'agent se souvient des interactions passées
- Personnalisation utilisateur : les préférences et les patterns sont retenus
- Contexte accumulé : l'agent s'améliore au fil du temps en stockant plus
Où ça échoue :
- La recherche est probabiliste. Le système retourne des souvenirs similaires à la requête courante, pas nécessairement les plus pertinents ou les plus récents
- Pas de structure. Les souvenirs sont stockés comme du texte plat ou des embeddings. Le système ne comprend pas les relations entre les souvenirs
- Pas de raisonnement. Vous pouvez récupérer un souvenir, mais vous ne pouvez pas demander « lesquels de mes souvenirs se contredisent ? » ou « qu'est-ce qui a changé depuis la dernière fois que j'ai vu ce client ? »
- Obsolescence. Les anciens souvenirs ne se mettent pas automatiquement à jour quand la réalité sous-jacente change. L'agent pourrait se rappeler un fait qui n'est plus vrai
- La qualité se dégrade avec l'échelle. Plus le store de mémoire grandit, plus la recherche devient bruitée. Plus de souvenirs signifie plus de potentiel pour des résultats non pertinents ou contradictoires
La mémoire à long terme est là où la plupart des architectures d'agents commencent à peiner. Les outils existent, mais ils traitent la mémoire comme un problème de recherche. Ils répondent à « de quoi je me souviens qui ressemble à ça ? » quand l'agent a besoin de répondre à « qu'est-ce que je sais qui est pertinent ici, et comment ça se connecte à tout ce que je sais d'autre ? »
Couche 3 : Connaissances structurées (mémoire prête pour le raisonnement)
Les connaissances structurées sont la couche qui manque à la plupart des architectures d'agents. C'est la différence entre un agent qui se rappelle des informations et un agent qui les comprend.
Comment ça marche : Au lieu de stocker des souvenirs sous forme de texte ou d'embeddings, les connaissances sont organisées en entités, relations et règles :
- Les entités sont des objets typés : Client, Commande, Produit, Politique, avec des propriétés définies
- Les relations connectent les entités : le Client a passé la Commande, la Commande contient le Produit, le Produit est fabriqué par le Fournisseur
- Les règles encodent la logique métier : « à risque » = utilisation en baisse de 40% sur 90 jours ET a des tickets critiques ouverts
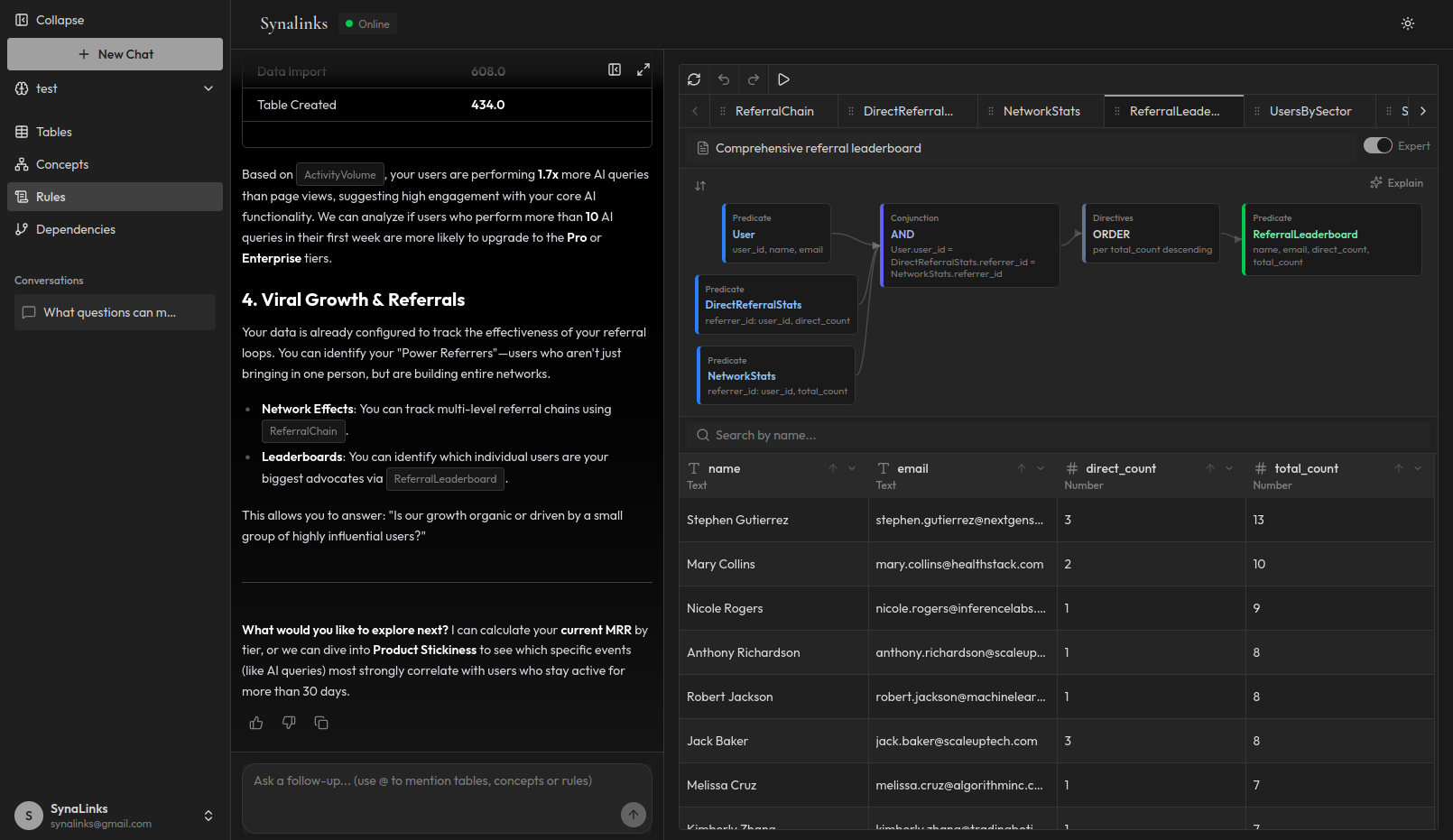
Cela crée un graphe de connaissances sur lequel l'agent peut raisonner, et pas simplement rechercher. Pour une comparaison approfondie, consultez notre guide RAG vs graphes de connaissances.
Ce que ça résout :
- Raisonnement multi-sauts : « Quels clients de fournisseurs avec des retards de livraison ont passé des commandes maintenant en retard ? » nécessite de traverser plusieurs relations. Un graphe de connaissances gère cela nativement
- Raisonnement temporel : « Qu'est-ce qui a changé dans le compte de ce client depuis le dernier trimestre ? » nécessite le suivi de l'état dans le temps, pas juste la récupération du dernier instantané
- Réponses déterministes : La même requête sur le même graphe de connaissances produit le même résultat. Pas de variation, pas d'hallucination sur les faits structurés
- Traçabilité : Chaque réponse est accompagnée d'une chaîne de raisonnement montrant quelles entités, relations et règles l'ont produite
- Cohérence : Les connaissances sont vérifiées et les contradictions sont résolues à l'ingestion, pas à la requête
Où ça échoue :
- Nécessite plus d'investissement initial pour modéliser le domaine
- Moins adapté aux informations purement non structurées
- L'écosystème est plus petit et plus récent comparé aux approches vectorielles
Comment les couches fonctionnent ensemble
Un système de mémoire d'agent bien architecturé utilise les trois couches, chacune gérant ce qu'elle fait le mieux :
La mémoire à court terme fournit le contexte conversationnel : que demande l'utilisateur, qu'a-t-il dit avant, quelle est la tâche en cours ?
La mémoire à long terme fournit le contexte rappelé des interactions passées : qu'a discuté cet utilisateur auparavant, quelles sont ses préférences, que s'est-il passé la dernière fois ?
Les connaissances structurées fournissent la vérité du domaine : quels sont les faits réels, comment les entités sont liées entre elles, quelles règles s'appliquent ?
Le raisonnement se fait à la couche de connaissances structurées. Les mémoires à court et long terme informent la requête, mais la réponse est déduite à partir de connaissances vérifiées via des règles définies.
Choisir la bonne architecture pour votre agent
Si votre agent gère des conversations en session unique (un chatbot qui répond à des questions depuis la doc) : mémoire à court terme + RAG vectoriel suffit.
Si votre agent doit se souvenir des utilisateurs entre les sessions (un assistant personnel, un bot orienté client) : ajoutez de la mémoire à long terme avec un store persistant.
Si votre agent doit raisonner sur des données métier et produire des réponses fiables et vérifiables (un agent customer success, un agent analytics, un système de conformité) : vous avez besoin de connaissances structurées. C'est non négociable si les mauvaises réponses ont des conséquences business.
La plupart des équipes commencent avec les couches 1 et 2 et se heurtent à un mur quand elles ont besoin de la couche 3. Les symptômes : réponses incohérentes, hallucinations sur les questions spécifiques au domaine, incapacité à expliquer comment l'agent est arrivé à une conclusion, et précision qui se dégrade à mesure que la base de connaissances grandit.
Comment Synalinks Memory s'intègre
Synalinks Memory est une solution de couche 3 : connaissances structurées avec raisonnement déterministe, conçue pour s'intégrer avec ce que vous utilisez déjà pour les couches 1 et 2.
Il prend vos sources de données (bases de données, tableurs, fichiers, API), les structure automatiquement en entités, relations et règles, et fournit un moteur de raisonnement que votre agent peut interroger via une API simple.
Vous gardez votre framework de chat existant pour la mémoire à court terme. Vous gardez votre store vectoriel existant pour le rappel à long terme si vous en avez besoin. Synalinks Memory ajoute la couche de connaissances structurées qui rend les réponses de votre agent déterministes, traçables et correctes.
C'est la pièce architecturale qui transforme un agent qui se souvient en un agent qui sait.
Les captures d'écran sont fournies à titre illustratif. Le produit final peut différer sur certains aspects. Les données présentées sont synthétiques et utilisées uniquement à des fins de démonstration.